In this post, I will explain the basic concept of LSTM for RNN cell and its application for sentiment analysis of sequence of words (or sentence).
Understanding components of LSTM
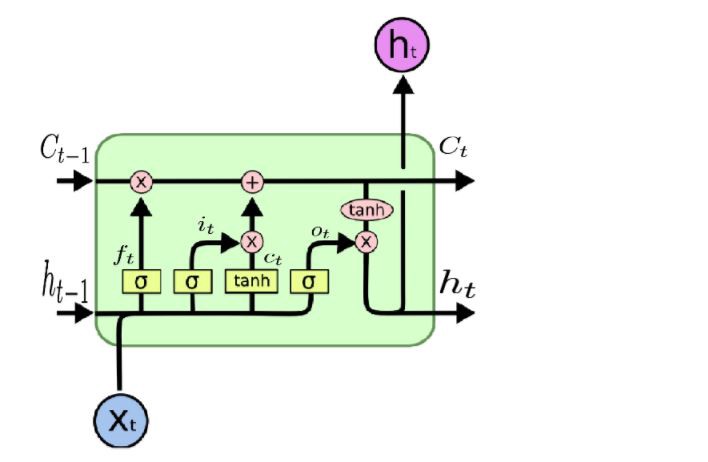
Source: Understanding architecture of LSTM cell from scratch with code
Image above is the representation of LSTM cell and its operations. The overall process of a cell depends on its gates.
Brief explanations:
- Ct-1 : Memory from previous block
- ht-1 : Output from previous block
- Xt : Input Vector
- ht : Output of current block
- Ct : Memory from current block
The first stage ft is called the forget gate. As the name said, it decides whether to remember or forget the input. This gate is controlled by sigmoid activation function which produce value of 0 and 1.
| Value | What it does |
|---|---|
| 0 | Forget input |
| 1 | Remember input |
There are no in-between numbers. Hence, there are no other choices other than forgetting or remember.
The second stage, which is the result of it and ct is the new memory stage. Tanh activation function is used at ct because it will never go to 0. So, there will always be “something”.
The last part is the output of the network. There is another sigmoid function used. It will decide which information is going to the next stage. Then, the data will go through a tanh function, which produces values needed.
Using LSTM for sentiment analysis
Let’s see if the model is able to perform sequence learning to decide Good and Bad reviews.
In this example, i will be using:
- IMDB Keras dataset
- Keras with Tensorflow backend for modelling
Explore Data
Start by loading IMDB dataset
from tensorflow.keras.datasets import imdb
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=10000)
I set the maximum words to be 10000. This parameter will make the function to return only the top 10000 frequent words from the corpus.
Let’s explore the loaded data
print('=== Data ====\n{}\n\n=== Sentiment ====\n{}\n\n{}'.format(
X_train[5], y_train[5], type(X_train)))
# Default value in load_data
INDEX_FROM = 3
# Download word index and prepare word id
word2id = imdb.get_word_index()
word2id = {word:(word_id + INDEX_FROM) for (word, word_id) in word2id.items()}
# Labelling predefined value to prevent error
word2id["<PAD>"] = 0
word2id["<START>"] = 1
word2id["<UNK>"] = 2
word2id["<UNUSED>"] = 3
# Prepare id to word
id2word = {value:key for key, value in word2id.items()}
print('=== Tokenized sentences words ===')
print(' '.join(id2word[word_id] for word_id in X_train[5]))
Output:
=== Data ====
[1, 778, 128, 74, 12, 630, 163, 15, 4, 1766, 7982, 1051, 2, 32, 85, 156, 45, 40, 148, 139, 121, 664, 665, 10, 10, 1361, 173, 4, 749, 2, 16, 3804, 8, 4, 226, 65, 12, 43, 127, 24, 2, 10, 10]
=== Sentiment ====
0
<class 'numpy.ndarray'>
=== Tokenized sentences words ===
<START> begins better than it ends funny that the russian submarine crew <UNK> all other actors it's like those scenes where documentary shots br br spoiler part the message <UNK> was contrary to the whole story it just does not <UNK> br br
It looks like the corpus has been preprocessed to numpy array. Every review is represented as word indexes sequence. The sentiment is in binary. So, there is no need to perform label encoding.
Other things to observe from the reconstructed sentence are <start> and <UNK>.
<start>: This is to set the boundary such as informing the starting point of a sentence<UNK>: Label new words that is not present in the English dictionary.
Define Model
Before defining the model, we need to make sure training and testing data to have sequences of the same length. This process is required because it defines the model input length.
Not having the same length will cause input shape error. pad_sequences will make sure all data have the same length by adding paddings.
from tensorflow.keras.preprocessing.sequence import pad_sequences
pad_size = 1000
X_train_pad = pad_sequences(X_train, maxlen=pad_size)
X_test_pad = pad_sequences(X_test, maxlen=pad_size)
Defining maxlen will set the desired maximum length of every sequence. This value will be used as the input length of the model.
vocab_size=len(word2id)
embedding_size=32
output_units = 1
model=Sequential()
model.add(Embedding(input_dim=vocab_size, output_dim=embedding_size,
input_length=pad_size))
model.add(LSTM(units=100))
model.add(Dense(output_units, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
print(model.summary())
Function usage
Embedding Layer
The model cannot work with strings. This layer change every word(string) to vector. So, a sentence(sequence of word) is represented as sequence of vectors.
The weights are trainable.
LSTM layer
This is the LSTM layer explained at the begining of the post.
Dense layer
The standard neural network.
I am using one output class to classify 0 and 1 as Negative and Positive. Because the output value will only be in the range of 0 to 1, I decide to use a Sigmoid activation function.
Compile
For compilation, adam optimizer is used to change neural network attributes such as weights and hopefully minimize losses along the way.
Output
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 1000, 32) 2834816
_________________________________________________________________
lstm (LSTM) (None, 100) 53200
_________________________________________________________________
dense (Dense) (None, 1) 101
=================================================================
Total params: 2,888,117
Trainable params: 2,888,117
Non-trainable params: 0
_________________________________________________________________
None
Perform Training and Evaluation
Befor running the model, data needs to be divided into training and validation. I use 80% of the data for training and 20 for validation.
train_size = math.ceil(0.8 * len(X_train))
X, y = X_train_pad[:train_size], y_train[:train_size]
X_val, y_val = X_train_pad[train_size:], y_train[train_size:]
Now it’s time to train
batch_size = 64
epochs = 5
model.fit(X, y, validation_data=(X_val, y_val), batch_size=batch_size,
epochs=epochs, shuffle=True)
Output
Train on 20000 samples, validate on 5000 samples
Epoch 1/5
20000/20000 [==============================] - 20s 987us/sample - loss: 0.4444 - accuracy: 0.7983 - val_loss: 0.2997 - val_accuracy: 0.8780
Epoch 2/5
20000/20000 [==============================] - 20s 1ms/sample - loss: 0.2677 - accuracy: 0.8945 - val_loss: 0.2820 - val_accuracy: 0.8846
Epoch 3/5
20000/20000 [==============================] - 20s 977us/sample - loss: 0.2296 - accuracy: 0.9105 - val_loss: 0.3176 - val_accuracy: 0.8784
Epoch 4/5
20000/20000 [==============================] - 19s 971us/sample - loss: 0.1684 - accuracy: 0.9392 - val_loss: 0.3305 - val_accuracy: 0.8832
Epoch 5/5
20000/20000 [==============================] - 20s 996us/sample - loss: 0.1714 - accuracy: 0.9338 - val_loss: 0.3900 - val_accuracy: 0.8246
Finally, evaluate the trained model using test data
scores = model.evaluate(X_test_pad, y_test, verbose=0)
print('Model Accuracy:', scores[1])
Output
Model Accuracy: 0.81556
That’s it. The result is quite impressive. It shows that the model can detect Positive and Negative review correctly for 81%.
Conclusion
The ability to pass information from one state to another is useful to understand texts. The application is not only for texts. Any data interpretation that requires sequence understanding, such as time series modelling can use LSTM modelling.
View full code here