When to use them? How do I know if this is the right algorithm to use? Asking these questions is crucial when developing a predictive model. I’ve encountered a few experiences where classification gives me higher accuracy during training. When predicting, regression is more accurate. Sometimes, the other way around.
I would like to think that accuracy metrics do not matter if we are using the “wrong” algorithm. Instead, “lower” accuracy using the right algorithm for the prediction goals should be focused.
Imagine this; Would anyone use a motorbike to pick up four friends? Going to the place is faster than using a car. But, it is still not the right tool. Use the right tool for the right goals.
What I have learned so far, the first step to build a prediction model is to understand the goal. Take an example of weather data. I need to ask myself:
- Am I predicting the possibilities of raining today? or
- Am I trying to predict if today will be raining or not?
Then I can decide which algorithm to use.
Simply said. Regression predicts continuous output. Classification predicts discrete output.
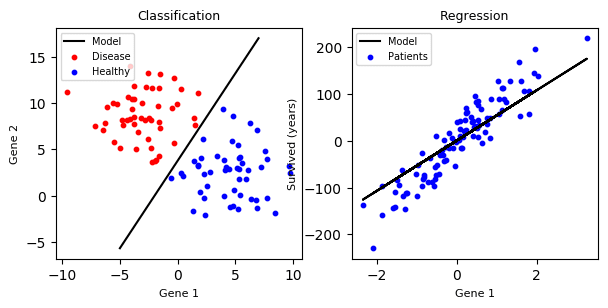
Regression takes input data x to find the response, y classification takes input data x and finds which group, a class does it belong to, y.
Back to the example of weather to predict possibilities. The possibilities(%) lies between 0 - 100%, which means it is a continuous output, thus, regression. But, can I use classification for this data? Yes!
Then, the question is, how do I label every data? If I am crazy enough, I can label 0%, 1%, 2% until 100%. That will give me 101 labels and surely classifying them will be hard. Plus, I have to consider if they fall in between such as 55%. So, classification is usable, but not practical.
Again, looking at the next example. Predict if today will rain or not? Or “raining? Yes or no?”. The goal is to predict two classes. and these classes can be labelled as:
- 0 - 50% (no today will not rain)
- 51 - 100% (yes today will rain) The output is discrete as I just want to know the two outcomes.
From the example above, a model that requires too much (infinite) number of classes would work better with regression. And whenever, I need to build a model that group the data, classification is the way to go.