In this post, I would like to write about the differences in CNN’s application for image versus text.
Convolutional Neural Network or CNN is well known for its ability to detect local features. At the time of writing, this algorithm is used in every SOTA image classification model. However, it is not a well-known method in the NLP classification domain.
How CNN works for image
If someone asks me to describe CNN in simple terms, I would say “algorithm that search for local features in an image.” Basically, it is observing signs of shapes. This approach is beneficial in a classification task.
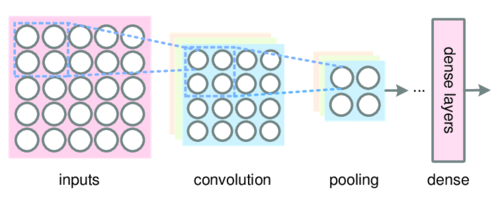
The usual classification process of an image is usually as below:
1. Convolution Layer
2. Max Pooling
3. Matrix Flattening
4. Fully Connected layer
{kind=link}
Convolutional Layer
Humans classify images by observing shapes to form an object. Almost the same idea is applied here. The only difference is CNN find a much more detailed representation of the shape.
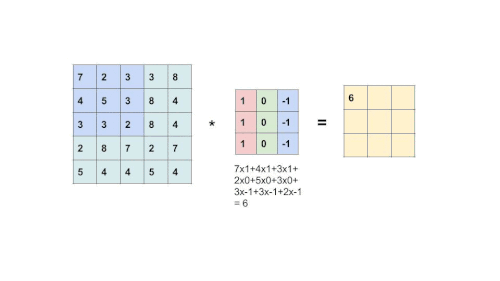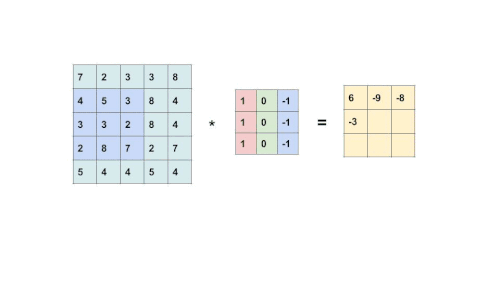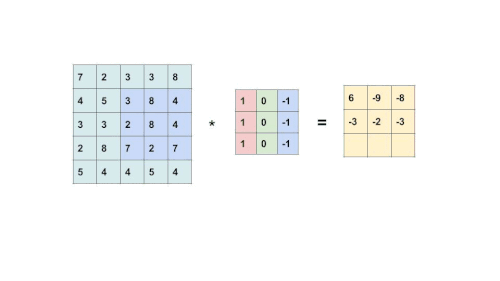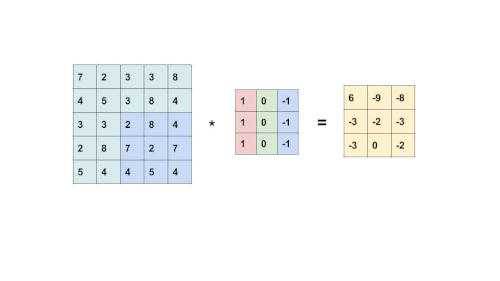
It uses a feature detector called filter(also known as the kernel). At the beginning of training, all filters are randomly initialized. Then, the model will tune the filter according to what features best describe the label.
The filter slides throughout the input image to detect patterns. This process is called convolving.
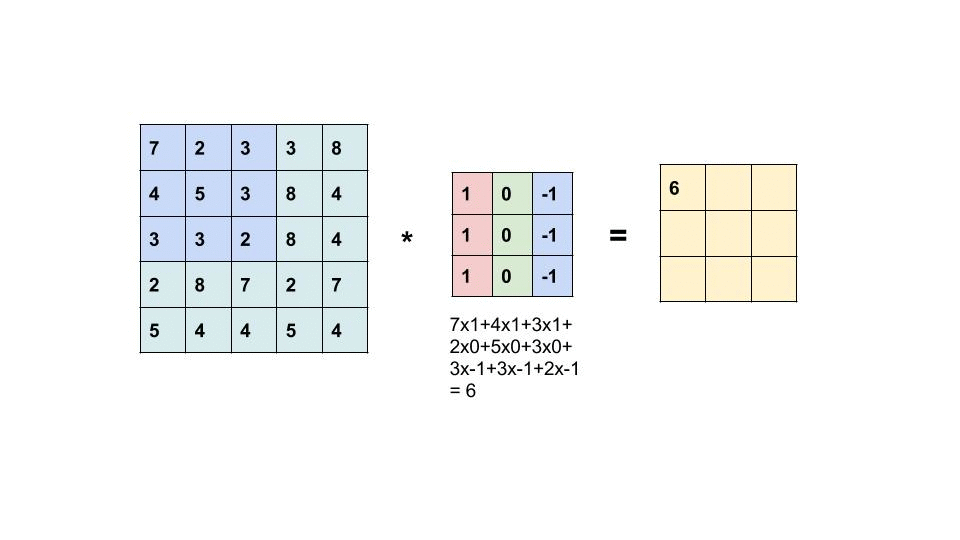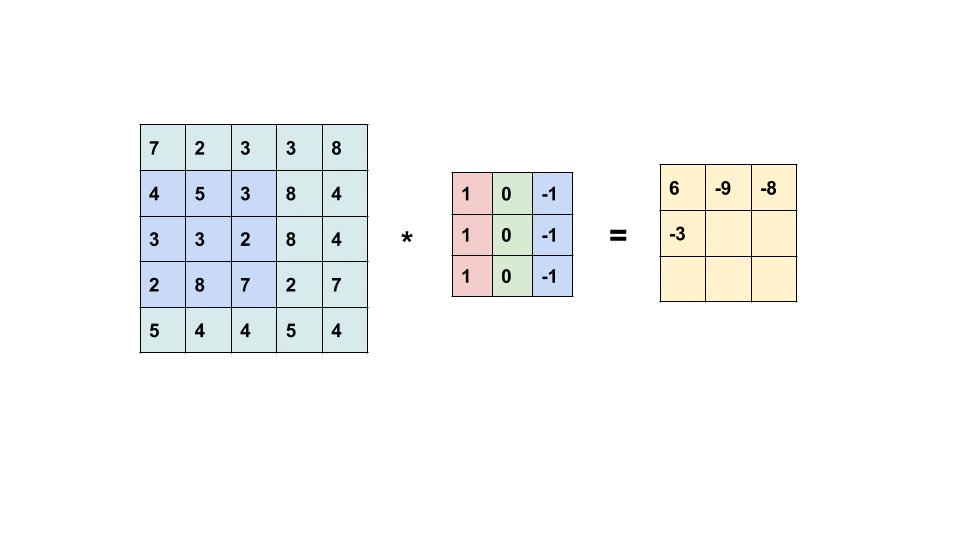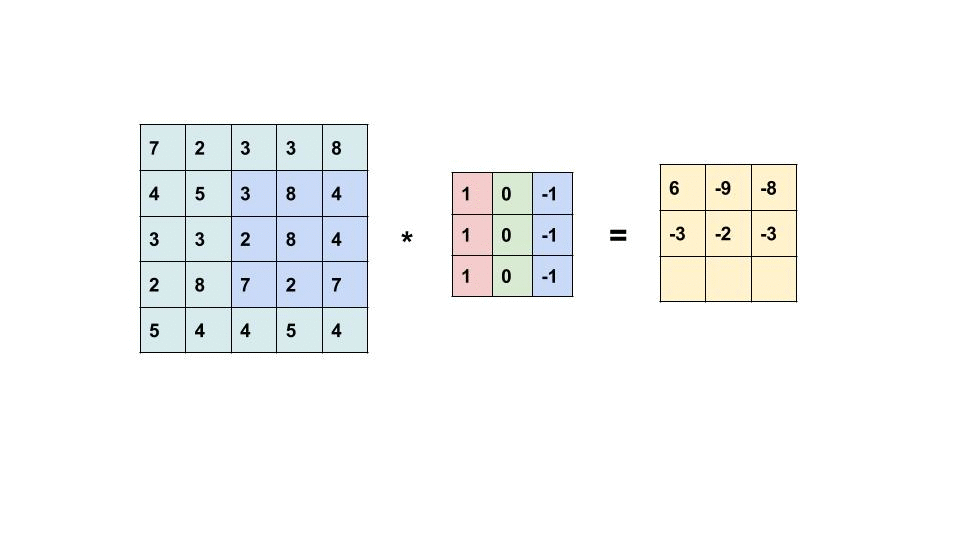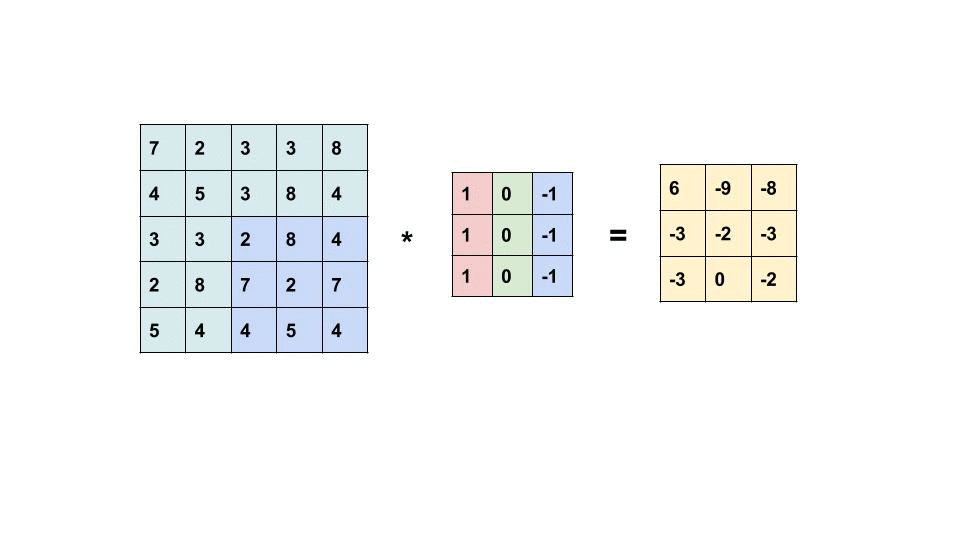{kind=link}
This is an element-wise multiplication of input(a matrix) at a specific location and filter(also a matrix). Every filter will produce its own feature map. As the filter becomes more descriptive, the feature map will show a better summary of the image.
Max Pooling
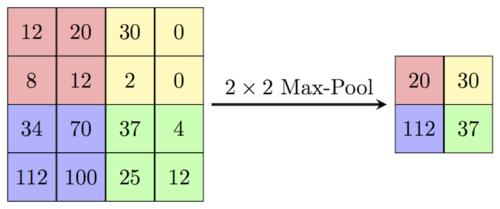
Image Source: ComputerScienceWiki
{kind=link}
The feature map holds the summary of the input image with respect to the filter. The bigger the image, the more result the CNN layer produces, which means the model will have more parameters and will take longer to process.
This problem can be solved by pooling the information. The biggest number from the feature map will be taken to describe the feature. The bigger the number, the more prominent the features. In this way, the size of the image is reduced without losing too much information.
Matrix Flatening
At some point, the output must be a vector or a 1D matrix. This is where flattening does its job. From the previous stage, we understand that the output is still a 2D matrix. The matrix will be flattened by rearranging it according to its position in the space.

Image Source: Towards Data Science
The output will be a vector.
Fully Connected Layer
This is the standard neural networks, which consist of tunable parameters and connected to the output layer.
The main difference between Image and Text data
Before going to CNN for texts, we need to understand the difference between both data types (image vs text). What we know so far is CNN is used to detect features of a matrix. Thus, both image and text data have to be in the form of a 2D matrix.
Let’s assume the input matrix has a size of 128 by 128. What can we understand from that?
Image
For image, this can be understood as an image of having a width of 128 pixels and a length of 128 pixels. A square image.

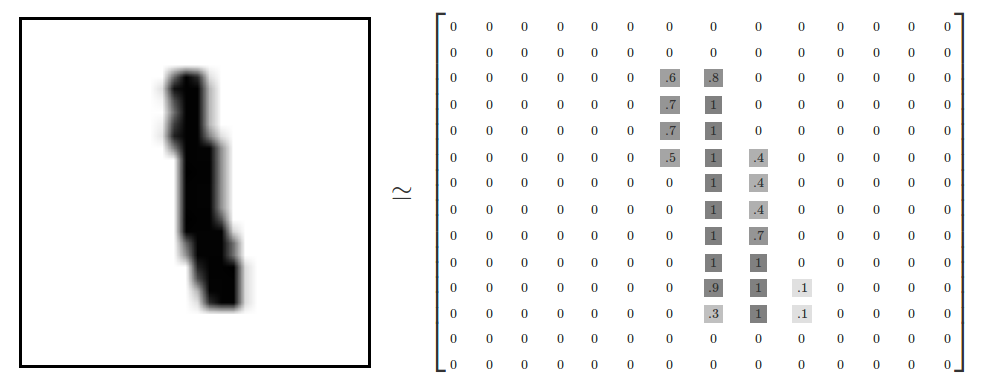{kind=link}
Further observation tells us that every pixel surrounding a pixel (top, bottom, left, right, top-right, bottom-right, etc.) contributes to the whole image’s meaning. This is why the filter slides sideways and downwards because it needs to consider the neighboring pixels.
Text
Text data has a different representation. Since words are used in sequences, also known as sentences, every input data must be in sequential manners. That means, every sentence should form an input matrix according to the input size of the model.
The number of words in a sentence + padding makes up the length of the input matrix. The padding is added to match the input neurons. For model with a length of 7 inputs, the data matrix size should be as below:
Input Sentence: This is a ball
Input matrix. Size (7, 4).
This [0.1, 0.2, 0.01, 0.7]
is [0.3, 0.21, 0.34, 0.23]
a [0.42, 0.17, 0.74, 0.57]
ball [0.11, 0.38, 0.14, 0.24]
pad [0, 0, 0, 0]
pad [0, 0, 0, 0]
pad [0, 0, 0, 0]
In NLP tasks, there are two ways of forming input:
- Word level: Sentences are describe bassed on words
- Character level: Sentences are describe based on character. i.e., letters, punctuations
For this post, I will use the word level. The usual method to describe words is using word embeddings. The main idea of word embedding is to represent a word in the vector space.

{kind=link}
Each word is represented as a one by N vector. For the example above, the N value is 4. There is no rule of thumb for the number. The length of the BERT embeddings is 768. This value is experimental.
Going back to the first example, if the size of text input data is 128 by 128, it means the maximum length of sentence is 128 words, and the length of every word embeddings is 128.
How CNN works for Text
If you get the idea of word embedding, you will understand two things:
- Every row represents a word
- Matrix columns mean nothing. They are just points to represent the word in the vector space.
That means, using a filter that slides from left to right is useless because there are no column-wise dependencies. A word’s features in a sentence are its neighboring words, also called context words, which are arranged row-wise(top to bottom).
Brief explanation of context words
If you are familiar with Word2Vec, a parameter called window size determines how many words to the left and right are considered contexts. For example:
Sentence: The brown fox jump over the red fence
window size = 2
If we are checking for the word jump, the context words are:
- 2 words to its left:
brown, fox - 2 words to its right:
over, the
CNN filter for text
Because words are arranged row-wise, the filter should slide from top to bottom. The value of context words determines the variation of the feature detector. For example, one filter may slide over three words at a time, and the other will slide through 5 words at a time.

Pooling
This layer serves the same purpose as in the image, to reduce size. Only the maximum value will be taken to represent the feature. As you can see, the output is already in vector format. So, there is no need to apply any more flatten process.
Fully Connected Layer
And the last layer should be the standard neural network, which is connected to the output neurons.

{kind=link}
Summary of CNN for text

Conclusion
In this post, I hope:
- You gain useful insights regarding the intuition of CNN for both applications.
- You see the difference in the process
- You understand the input format of both processes.